在昨天的这个回答之后:
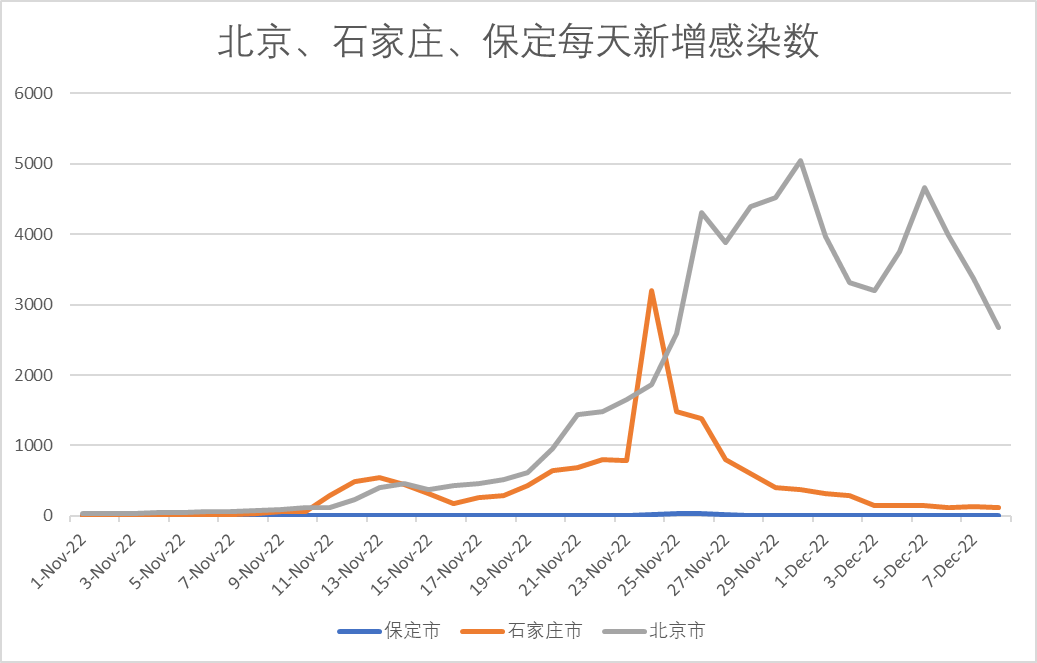
我又对台湾地区、香港特别行政区和日本的感染情况与“发烧”搜索指数进行了分析,发现一个可能可以帮助预测感染高峰期的方法:
1)将Google搜索指数分为疫情期间和非疫情期间,非疫情期间的发烧指数平均数为 ,将疫情期间的搜索指数做以下处理后加总,计算一个数值
其中S的含义是这样的:如果发烧的搜索是发烧人口的一个相对稳定的比例,且在非疫情期间发烧人口是总人口的相对稳定的比例,那么S就正比于疫情感染的人口占总人口的比例,我们把它叫做“超额发烧搜索指数累计面积”
2)下图列出了台湾地区、香港特别行政区以及日本的“超额发烧搜索指数累计面积”,即下图橙色面积、蓝色面积和灰色面积。
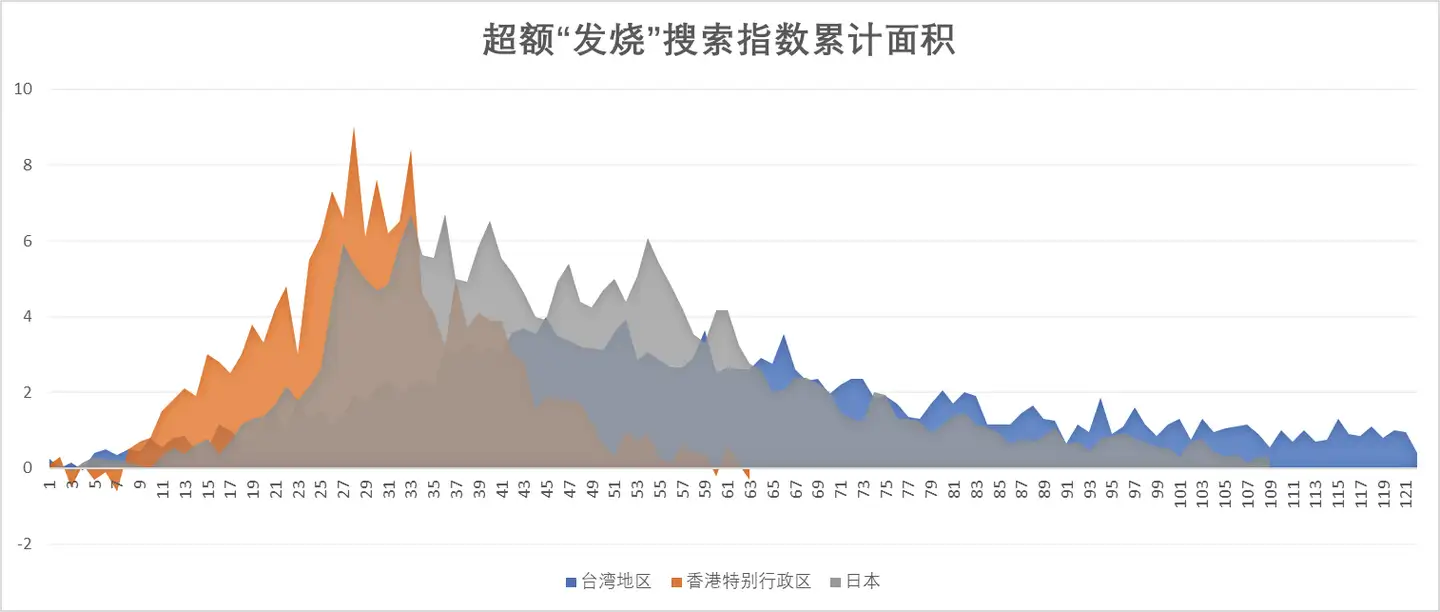
我们发现在这三个地区,当疫情达到顶峰时,这个“超额发烧搜索指数累计面积”的数值全部刚好达到80。这两个地区第一波疫情结束时,香港特别行政区的面积达到了160,台湾地区的面积达到了200,日本的最终面积是250。
3)如果用百度搜索指数做类似的研究会有什么效果呢?我使用了本轮疫情进入群体感染最快、最早的石家庄、邢台和保定做了计算:
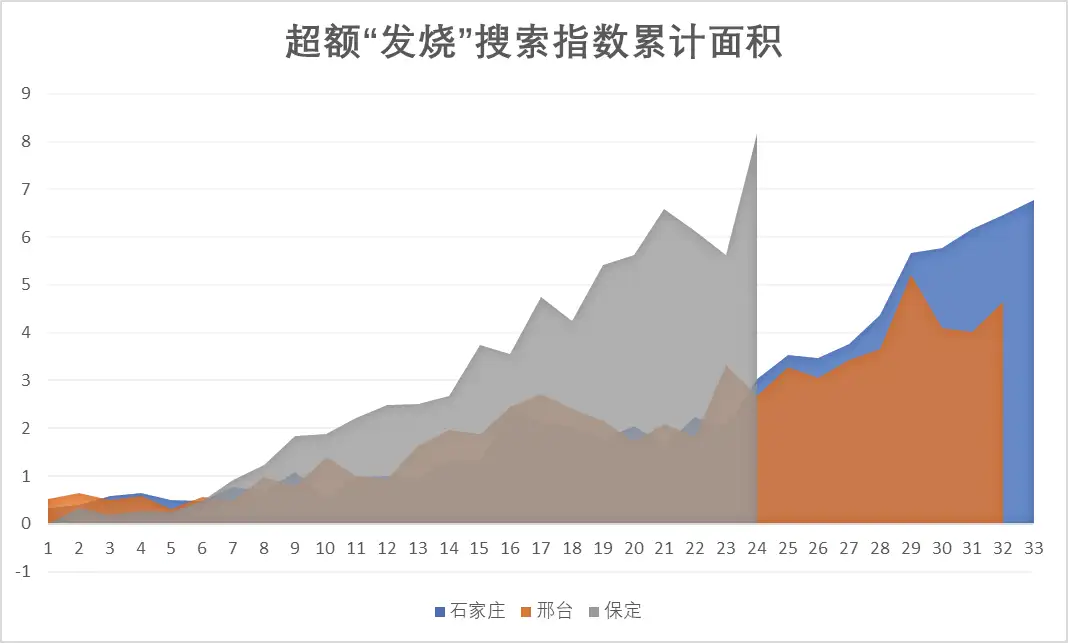
可以算出,从疫情开始后计算,石家庄的“超额发烧搜索指数累计面积”已经达到了76,邢台已经达到了67,保定也达到了71。由此来看,百度搜索指数和Google指数分别算出的“超额发烧搜索指数累计面积”,至少是在一个差不多的数量级上。
4)考虑到保定、石家庄、邢台等地的发烧指数仍然在上升,以及百度搜索指数和Google指数的差异,我们比较保守地将100作为疫情达峰时的“超额发烧搜索指数累计面积”,将250作为第一轮疫情结束时的“超额发烧搜索指数累计面积”。那么我们通过每个城市的搜索指数累计增长,累计速度,就可以算出现在每一个有疫情的城市疫情达峰的时间,以及疫情结束的时间。
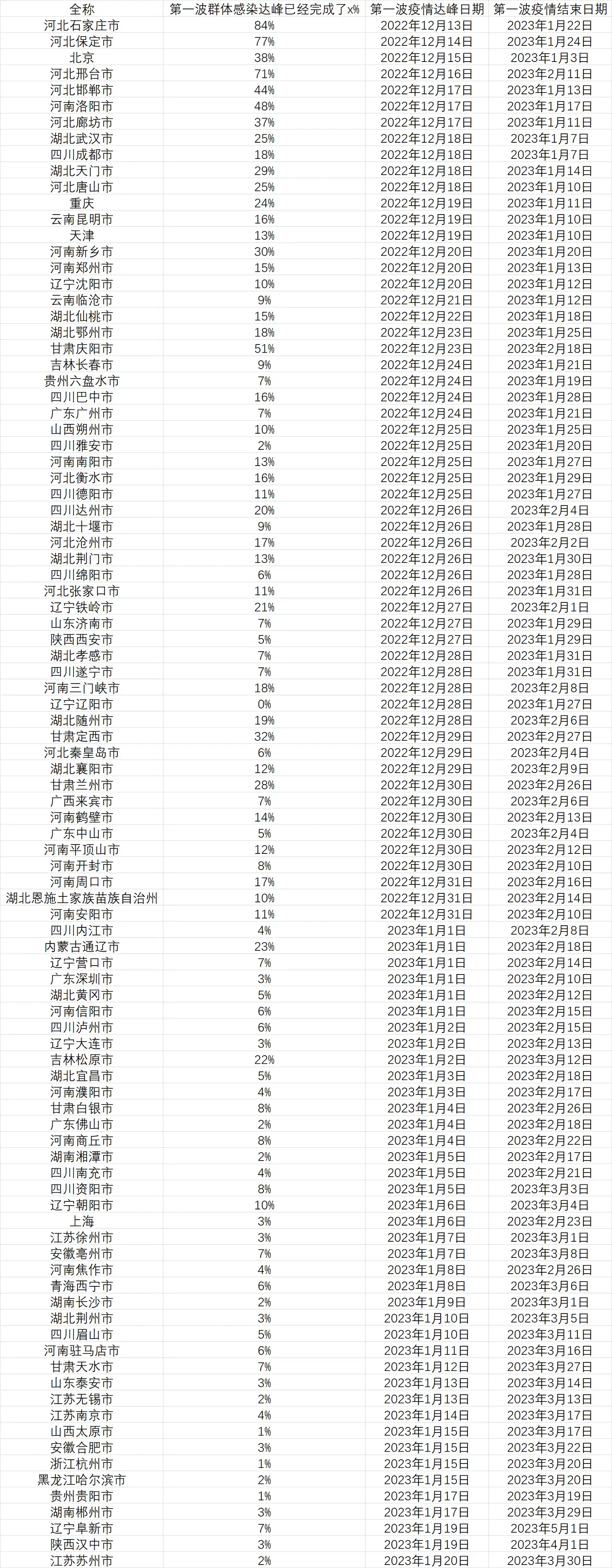
这是计算的结果,列出了所有能在明年春节前达峰的城市以及这些城市在达峰前已经感染的人口比例(截止至12月10日)。
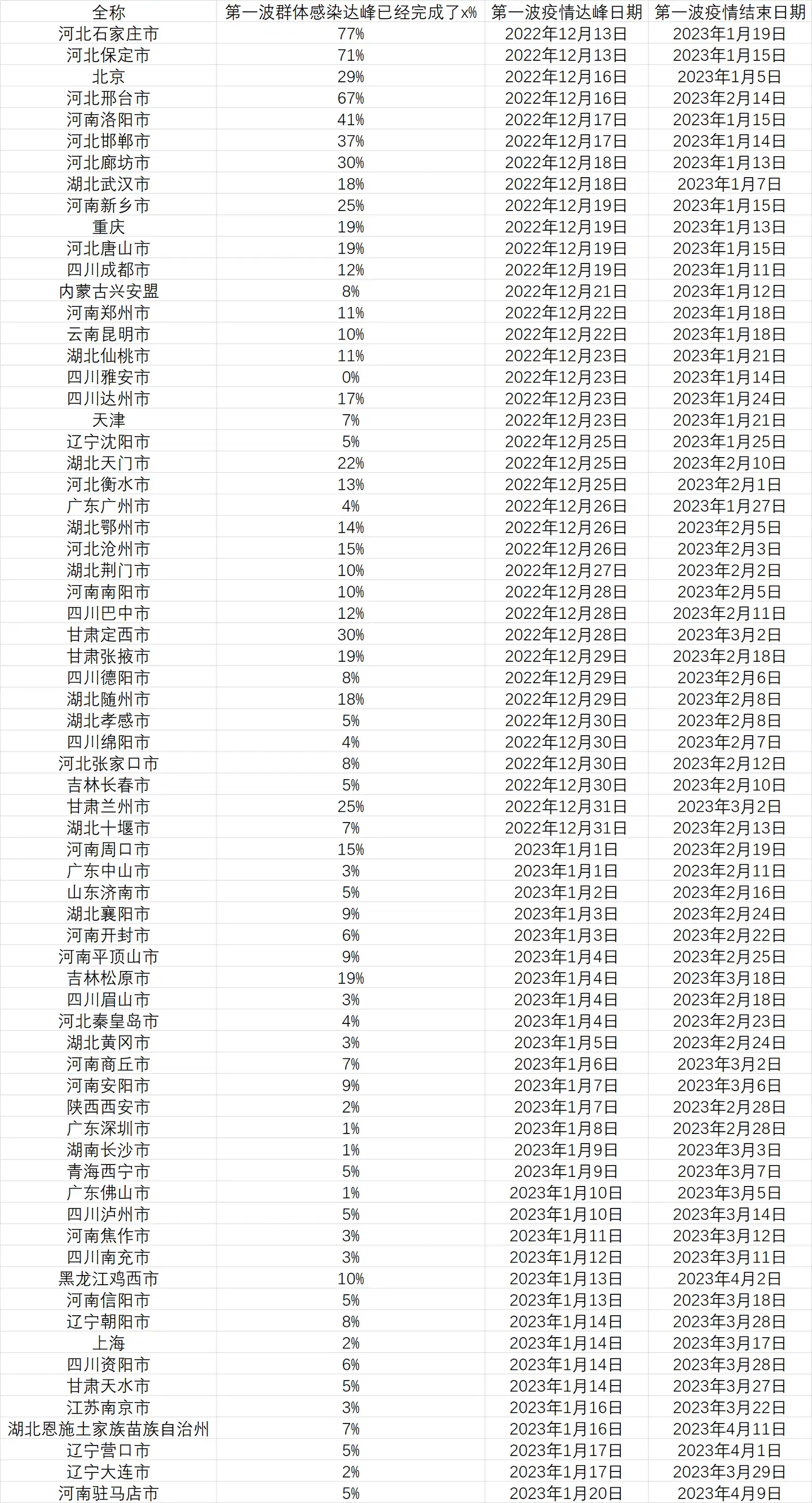
2022年12月12日更新:
2022年12月13日更新:
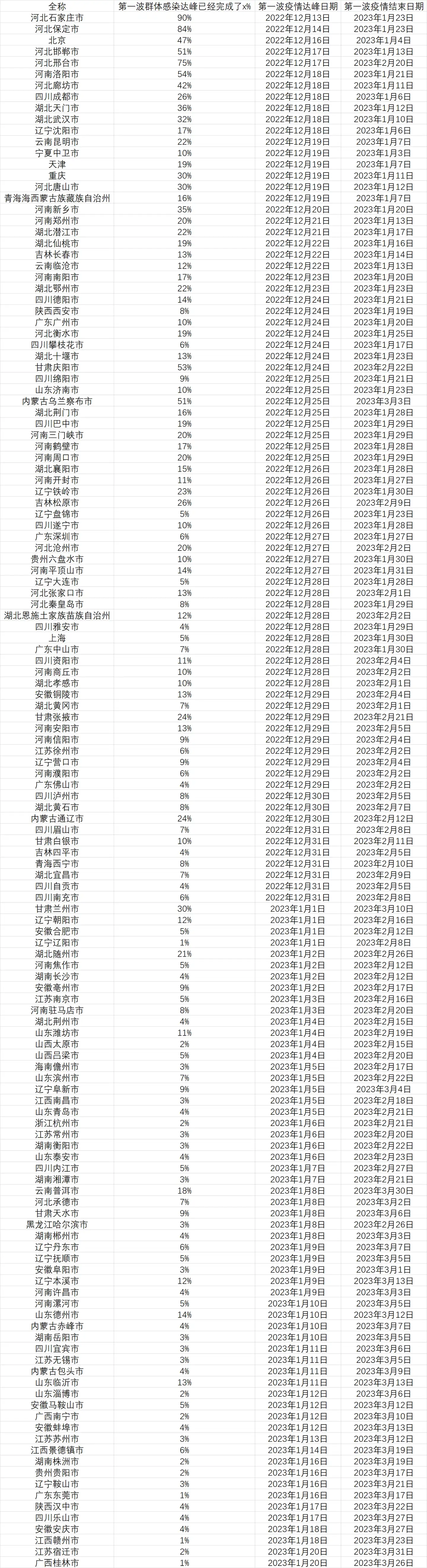
12月14日更新:
今天的更新有三个大的改动。
第一是加入了巨量算数指标修正了一些城市,加入了一些之前数据不足的城市。
第二是我将过峰的“超额发烧搜索累计面积”修正回了80。
之前的几张表格中,保守起见,这个数值我使用的是100,他会使一些城市过峰偏慢。但从这几天的数据看,石家庄、保定等地已经过峰,这说明中国内地城市居民,在非疫情-疫情的变化中,搜索行为的变化上和香港特别行政区、台湾地区的居民在同样时期的变化是非常类似的。因此一些城市会在今天的表格中有所提前。
第三是加入了“结束进度条”这一变量,代表已经度过疫情顶峰的城市在第一波疫情结束前可能还要走的路程。

12月15日更新:
今天按照行政区划代码的顺序做了排序,增加了一个变量“累计感染占总人口比值”。这个数值也是根据累计的超额搜索面积计算的。在“数据团+”小程序中也做了相应更新。一些人口较少的城市的搜索指数变化幅度较大,可能会导致数据波动。

12月16日更新:
今天修改了许多之前计算的bug,比如多段疫情被合并计算(例如新疆的一些城市被合并三个月疫情后出现了超过100的感染率),疫情结束时间的算法尾部过宽,一些小城市的缺失(比如济源、仙桃、吉林省吉林市)以及巨量算数的权重。头条系产品的许多数据来自被动推送,比如点击搜索框,出现一个“内马尔发烧了”,吸引用户点击后,可能就会造成一些地方的“发烧”搜索异常。我使用百度的全国指数作为基准整体修正了巨量算数,得到了一个更为稳健的结果。有些读者可能会注意到今天有一些城市的疫情过峰时间、结束时间都变长了,这一方面来自上面的几项bug修改的结果。当然,更重要的一方面原因是一些城市确实在压平曲线,尽量降低疫情的增速。快速过峰当然会使得这个城市能够较快地离开第一波疫情,但是同样也会造成医疗资源大量挤兑。力所能及地增加一些社交距离,虽然会让这个城市的疫情更持久,但总死亡也会降低,在第一波感染中,还是值得的。
这也是我们的模型最后一次大幅度修改,之后的数据就能保持相对稳定了。

12月17日更新:
1,增加了“新增感染占比”一项,表示当天新增的感染人口在总人口中的比重。虽然北京等地的感染已经过峰,但是全国各地的疫情正在快速上升,12月16号这一天,全国增加了近4000万感染。
2,由于图片大小限制,不得不去掉了人口在50万以下的城市。有需要的话可以在“数据团+”的小程序中看到,在小程序中我另外增加了一项每日感染的预测曲线图。

数据不足,方法简陋,仅供参考。
沒有留言:
張貼留言